Home
Perceptual Optimization of Time-Frequency Audio Representations and Coding (POTION) is an international research project funded by:
- French National Agency for Research (Agence Nationale de la Recherche - ANR), Programme Blanc - Accords Bilatéraux 2013 - SIMI 3, Ref: ANR-13-IS03-0004-01
- Austrian Science Fund (Fonds zur Förderung der Wissenschaftlichen Forschung - FWF)
- Laboratory of Mechanics and Acoustics (LMA) - CNRS UPR 7051, France
- Acoustics Research Institute (ARI) - Austrian Academy of Sciences, Austria
One of the greatest challenges in signal processing is to develop efficient signal representations. Such a representation should extract relevant information and describe it with a minimal amount of data. In the specific context of sound processing, and especially in audio coding (like MP3 or AAC), where the goal is to minimize the size of binary data required for storage or transmission, it is desirable that the representation takes into account human auditory perception and allows perfect reconstruction with a controlled amount of perceived distortion.
Over the last decades, many psychoacoustical studies investigated auditory masking, an important property of auditory perception. Masking refers to the degradation of the detection threshold of a sound (target) in presence of another sound (masker). These results were used to develop models of either spectral or temporal masking. Attempts were made to simply combine these models to account for time-frequency (t-f) masking in perceptual audio codecs. We recently conducted psychoacoustical studies on t-f masking which revealed the inaccuracy of such simple models. These new data represent a crucial basis to account for masking effects in t-f representations of sounds.
T-f representations are standard tools in audio processing. Although, the development of a representation that is perception-based, perfectly invertible, and possibly with a minimum amount of redundancy, remains a challenge.
State-of-the art codecs use invertible and non-redundant representations (called t-f transforms, typically MDCT), but which are not perceptually motivated. Taking perception into account requires to add an earing model which is usually non-invertible, redundant, but perceptually motivated. The optimization algorithms are designed to make a connection between these two representations. But the main t-f transform and the hearing model usually weakly match, which probably degrades the efficiency of the coding process.
In this context, POTION addresses the following main questions:
- To what extent is it possible to obtain a perception-based (i.e. as close as possible to "what we get is what we hear") t-f representation of sound signals? Such a representation is essential for modeling complex masking interactions in the t-f domain and is expected to improve our understanding of auditory sound processing. Moreover, it is of fundamental interest for many audio applications involving sound analysis-synthesis.
- Is it possible to make such a t-f representation perfectly invertible with a minimum amount of redundancy? This would be of great interest in audio coding, because the main t-f transform and the hearing model could share the same representation.
- Is it possible to improve the performance of perceptual audio codecs ? In state-of-the art codecs, the data-reduction stage consists of the sub-quantization of t-f transform coefficients according to the output of the earing model, which mainly follows a spectral approach, although temporal masking effects are taken into account in some implementations. By combining an efficient perception-based t-f transform with a joint t-f masking model in an audio codec, we expect to achieve significant performance improvements.
The POTION project is structured in three main tasks:
- Perception-based t-f representation of audio signals: The main goal of this task is to investigate new linear t-f representations by exploiting the recently developed non-stationary Gabor theory as a mathematical background. These transforms should be designed so that t-f resolution mimics the t-f analysis properties of the auditory system and (i) perfect reconstruction is possible (ii) no redundancy is introduced or (iii) redundancy is exploited to maximize the coding efficiency. This task also investigates alternative methods that perform an adaptive decomposition of audio signal based on psycho-acoustic principles, but not necessary with perfect reconstruction.
- Development and implementation of a t-f masking model: Based on psychoacoustical data collected by the partners in previous projects and on literature data, a new complex model of t-f masking will be developed and implemented in a perceptually-motivated transform built in task 1. Additional psychoacoustical data required for the development of the model involving frequency, level, and duration effects in (t-f) masking for either single or multiple maskers will be collected. It will be calibrated and validated by listening tests with synthetic and real-world sounds.
- Optimization of perceptual audio codecs: This task represent the main application of the projet. It consists in the implementation of coding techniques in order to build complete coding/decoding algorithms taking into account the results from both tasks 1 and 2. These algorithms will be optimized and compated to state-of-the art using standard listening tests.
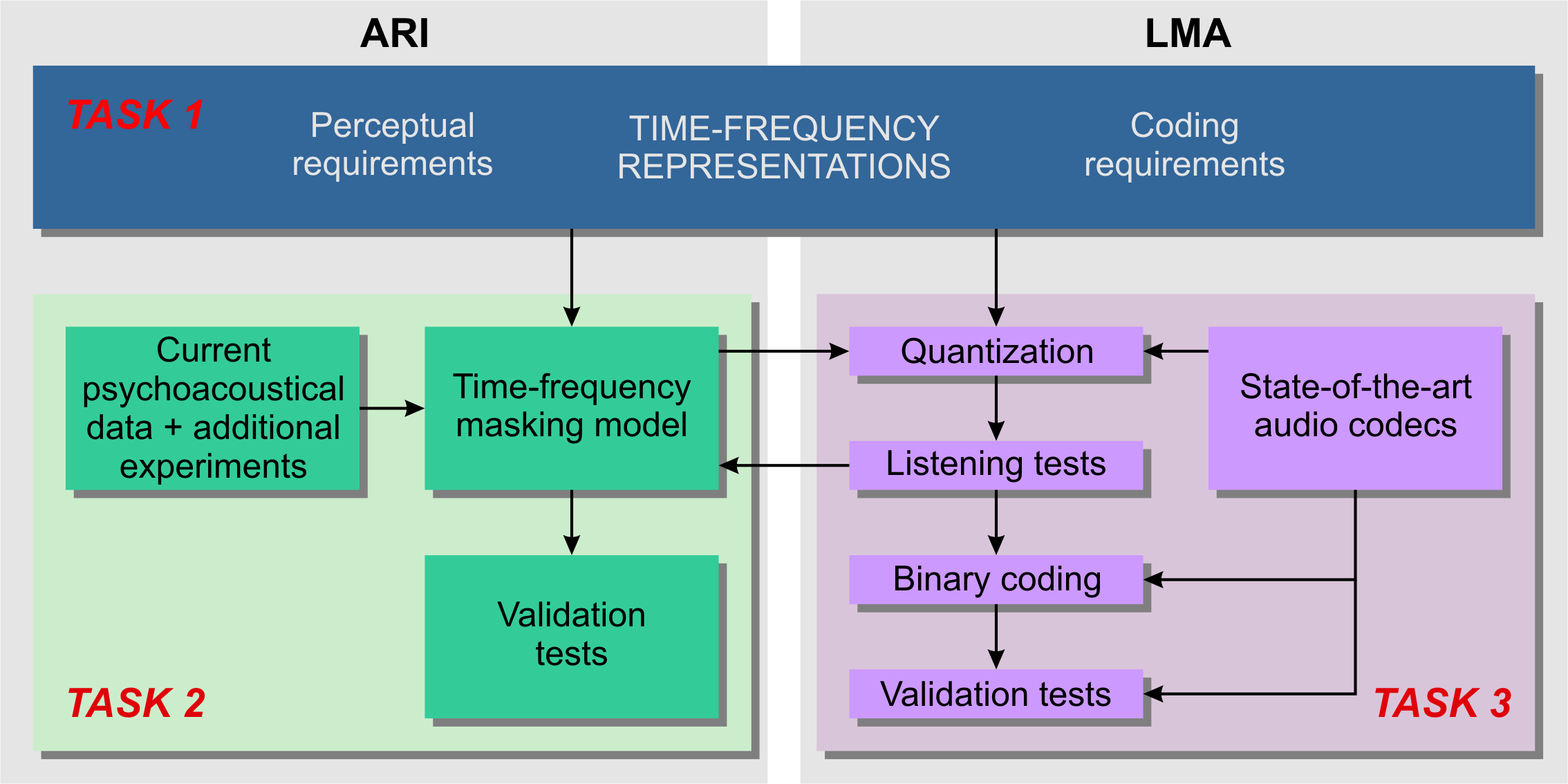
Tasks diagram of the POTION project